学习时长:
30min
课程收获:
了解如何将已有数据导入到 TiDB 集群中
了解 Lightning 工作原理、 Dumpling 工作原理
了解 Data Migration 工作原理
课程内容:
本课程简要介绍如何将已有数据导入到 TiDB 集群中。内容主要包括:用于导入全量数据的 TiDB Lightning 的概要介绍、功能特性、适用场景及使用示例;用于增量(或全量+增量)数据导入的 TiDB Data Migration 的概要介绍、功能特性、适用场景及使用示例。
Lightning 工作原理
TiDB Lightning 工具支持高速导入 Mydumper 和 CSV 文件格式的数据文件到 TiDB 集群,导入速度可达每小时 300 GB,是传统 SQL 导入方式的 3 倍多。
它有两个主要的目标使用场景:
- 大量新数据的快速导入
- 全量数据恢复
tidb-lightning 架构
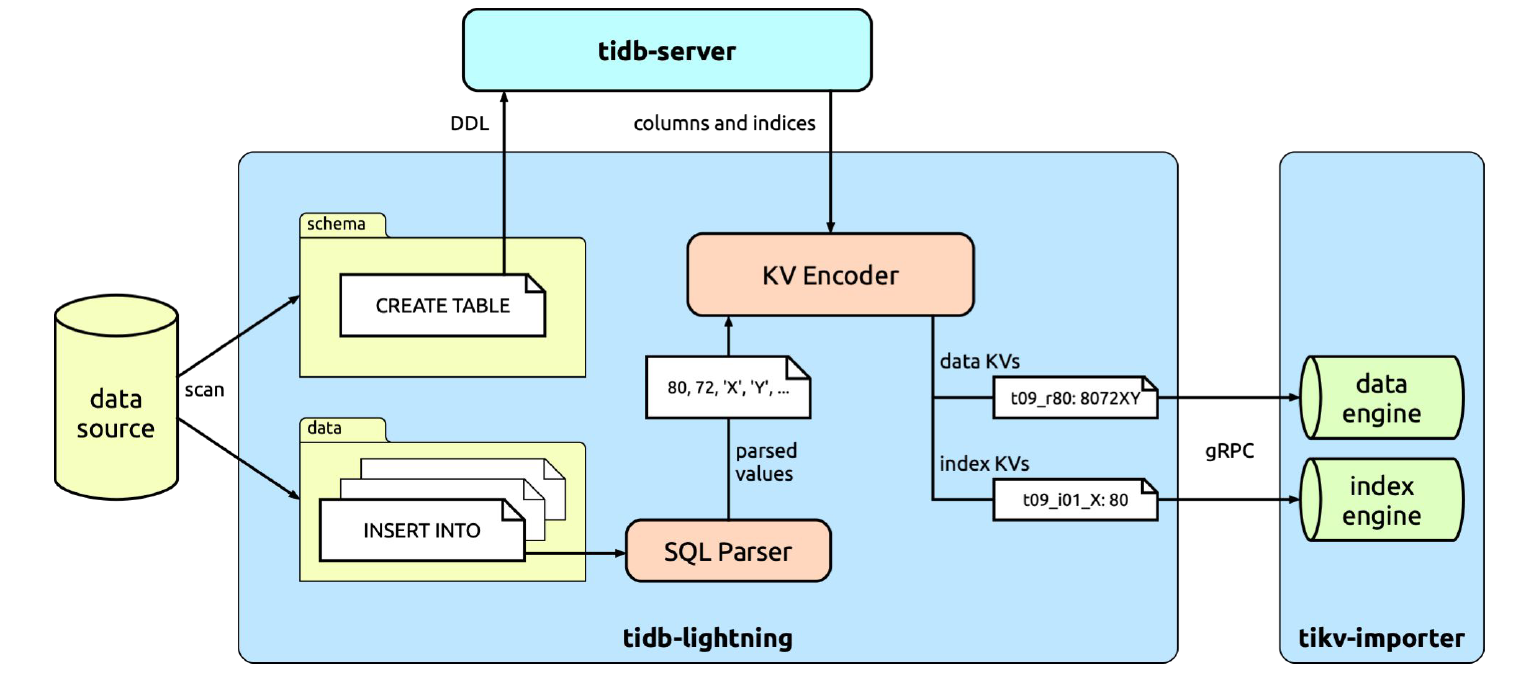
工作原理
tidb-lightning 会扫描数据文件,区分出结构文件(包含 CREATE TABLE 语句)和数据文件(包含 INSERT 语句)。结构文件的内容会直接发送到 TiDB,用于建立数据库和表。然后,tidb-lightning 会并发处理数据文件。这里,我们来具体看一下一张表的导入处理过程。
每张表的数据文件内容都是规律的 INSERT 语句,如下所示:
INSERT INTO `tbl` VALUES (1, 2, 3), (4, 5, 6), (7, 8, 9); |
tidb-lightning 会找出每一行的位置,并分配一个行号,这样即使没有定义主键的表也能够区分每一行。tidb-lightning 会直接借助 TiDB 实例把 SQL 转换为键值对,称为“键值编码器”(KV encoder)。与外部的 TiDB 集群不同,键值编码器是寄存在 tidb-lightning 进程内的,并使用内存存储;每执行完一个 INSERT 之后,tidb-lightning 可以直接读取内存获取转换后的键值对(这些键值对包含数据及索引),并发送到 tikv-importer。
并发设置
tidb-lightning 把数据文件拆分成多个能并发执行的小任务。下面的配置选项可以帮助调节这些任务的并发度:
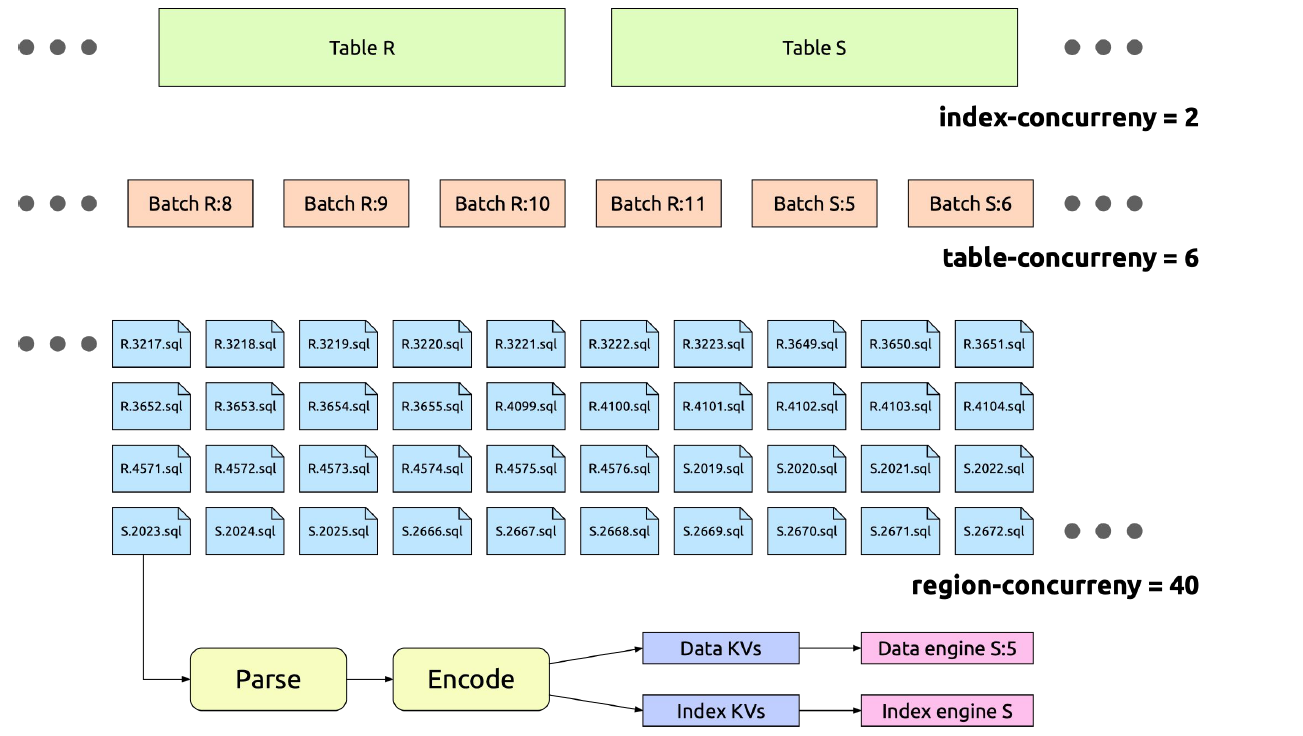
batch-size:对于很大的表,比如超过 5 TB 的表,如果一次性导入,可能会因为 tikv-importer 磁盘空间不足导致失败。tidb-lightning 会按照batch-size的配置对一个大表进行切分,导入过程中每个批次使用单独的引擎文件。batch-size不应该小于 100 GB,太小的话会使 region balance 和 leader balance 值升高,导致 Region 在 TiKV 不同节点之间频繁调度,浪费网络资源。table-concurrency:同时导入的批次个数。如上所述,每个表会按照batch-size切分成多个批次。index-concurrency:并行的索引引擎文件个数。table-concurrency+index-concurrency的总和必须小于 tikv-importer 的max-open-engines配置。io-concurrency:并发访问磁盘的 I/O 线程数。由于磁盘内部缓存容量有限,过高的并发度容易引发频繁的 cache miss,导致 I/O 延迟增大。因此,不建议将该值调整得太大。block-size:默认值为 64 KB。tidb-lightning 会一次性读取一个block-size大小的数据文件,然后进行编码。region-concurrency:每个批次的内部线程数。每个线程要执行读文件、编码和发送到 tikv-importer 等步骤。- 读文件会消耗 I/O 资源,需要调节
io-concurrency控制并发读取。 - 编码过程的瓶颈主要在 CPU,需要适当调整
region-conconcurrency配置。 - 举例来说,若一次编码处理耗时 50 毫秒,那么每秒只能进行 20 次编码。若
block-size为 64 KB,则单一 CPU 核每秒最多完成 1.28 MB 数据的编码处理。当region-concurrency设置为 60,则整体编码处理的极限速度约为每秒 75 MB。
- 读文件会消耗 I/O 资源,需要调节
Dumpling 工作原理
首先介绍一下 Dumpling 的诞生背景,在 Dumpling 诞生之前 PingCAP 提供了 Mydumper 的 fork 版本作为 TiDB 逻辑备份工具。随着 TiDB 生态的发展,Mydumper 由于种种先天不足,无法进一步满足实际应用中的需要。Mydumper 的不足主要有以下几点:
- 导出的数据格式无法满足 TiDB Lighting 数据导入工具的快速解析需要
- Mydumper 官方仓库年久失修,TiDB 并不倾向于在 fork 版本中继续提供新特性
- Mydumper 使用 C 语言及 GLib 开发,难以集成到与 Go 语言为主的 TiDB 生态工具,例如 DM 等
- Mydumper 本身采用的开源协议与 TiDB 所使用的开源协议不兼容
基于这些原因考虑,以 Dumpling 取而代之成为了更好的选择。Dumpling 将提供以下几个特性:
- 完全采用 Golang,与 TiDB 生态集成度高
- 能够提供 Mydumper 类似的功能,且支持并发高速导出 MySQL 协议兼容数据库数据
- 提供 SQL、CSV 等多种数据输出格式,以便于快速导出及导入
- 支持直接导出数据到云存储系统,比如 S3
一图胜千言,下面是 Dumpling 导出流程示意图:
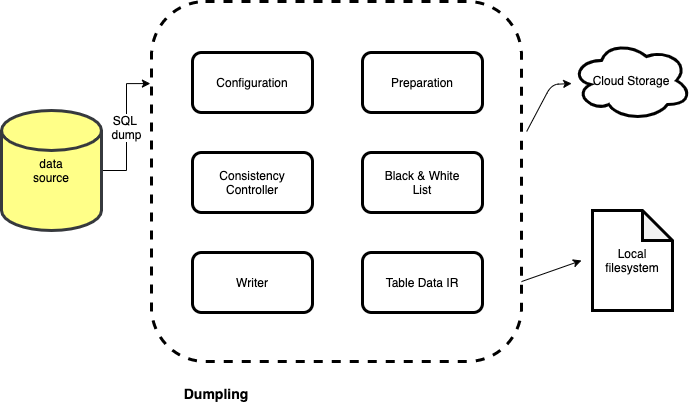
如图所示,Dumpling 分为六个比较重要的部分,分别负责配置解析、数据库信息预处理、一致性控制器、Black & White 列表、写控制器及表数据中间层表示。下面详细介绍一下各个部分的工作内容:
- 配置解析:处理用户通过命令行传入的参数
- 数据库信息预处理:在数据导出任务进行之前,获取数据库服务器版本、数据表、数据库视图等相关信息并进行预处理
- 一致性控制器:通过用户传入的一致性规则,在数据导出过程中保障数据一致性
- Black & White 列表:根据设置的规则过滤不需要导出的数据表
- 写控制器:负责将导出的数据写入到本地文件或云端存储系统
- 表数据中间表示层:中间表示层将数据表进行封装,提供一套 API 以供写控制器进行数据迭代写入
Data Migration 简介
TiDB Data Migration (DM) 是一体化的数据迁移任务管理平台,支持从 MySQL 或 MariaDB 到 TiDB 的全量数据迁移和增量数据复制。使用 DM 工具有利于简化错误处理流程,降低运维成本。
DM 2.0 相比于 1.0,主要有以下改进:
- 数据迁移任务的高可用,部分 DM-master、DM-worker 节点异常后仍能保证数据迁移任务的正常运行。
- 乐观协调模式下的 sharding DDL 可以在部分场景下减少 sharding DDL 同步过程中的延迟、支持上游数据库灰度变更等场景。
- 更好的易用性,包括新的错误处理机制及更清晰易读的错误信息与错误处理建议。
- 与上下游数据库及 DM 各组件间连接的 TLS 支持。
- 实验性地支持从 MySQL 8.0 迁移数据。
DM 架构
DM 主要包括三个组件:DM-master,DM-worker 和 dmctl。
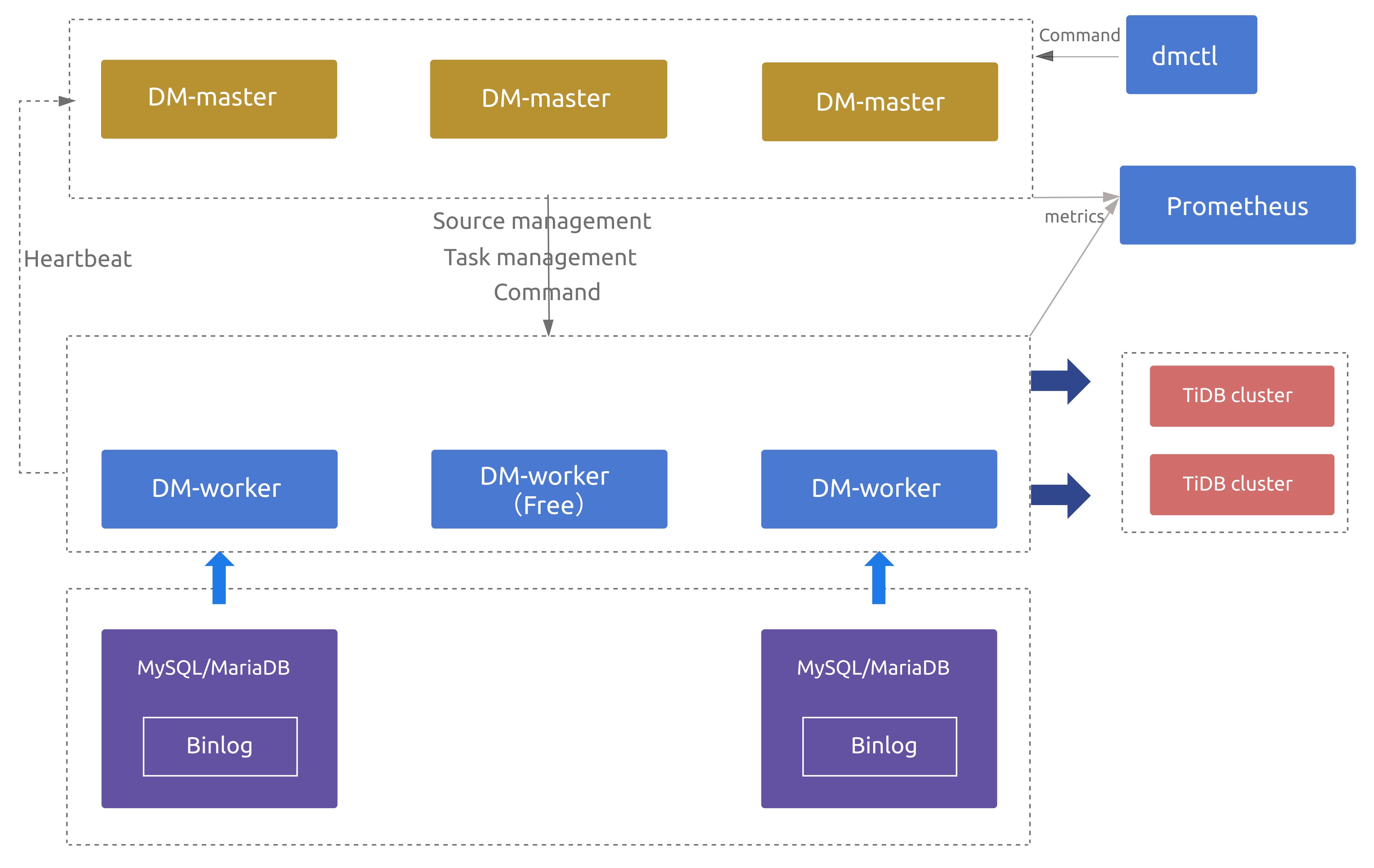
DM-master
DM-master 负责管理和调度数据迁移任务的各项操作。
- 保存 DM 集群的拓扑信息
- 监控 DM-worker 进程的运行状态
- 监控数据迁移任务的运行状态
- 提供数据迁移任务管理的统一入口
- 协调分库分表场景下各个实例分表的 DDL 迁移
DM-worker
DM-worker 负责执行具体的数据迁移任务。
- 将 binlog 数据持久化保存在本地
- 保存数据迁移子任务的配置信息
- 编排数据迁移子任务的运行
- 监控数据迁移子任务的运行状态
有关于 DM-worker 的更多介绍,详见 DM-worker 简介。
dmctl
dmctl 是用来控制 DM 集群的命令行工具。
- 创建、更新或删除数据迁移任务
- 查看数据迁移任务状态
- 处理数据迁移任务错误
- 校验数据迁移任务配置的正确性
高可用
当部署多个 DM-master 节点时,所有 DM-master 节点将使用内部嵌入的 etcd 组成集群。该 DM-master 集群用于存储集群节点信息、任务配置等元数据,同时通过 etcd 选举出 leader 节点。该 leader 节点用于提供集群管理、数据迁移任务管理相关的各类服务。因此,若可用的 DM-master 节点数超过部署节点的半数,即可正常提供服务。
当部署的 DM-worker 节点数超过上游 MySQL/MariaDB 节点数时,超出上游节点数的相关 DM-worker 节点默认将处于空闲状态。若某个 DM-worker 节点下线或与 DM-master leader 发生网络隔离,DM-master 能自动将与原 DM-worker 节点相关的数据迁移任务调度到其他空闲的 DM-worker 节点上(若原 DM-worker 节点为网络隔离状态,则其会自动停止相关的数据迁移任务);若无空闲的 DM-worker 节点可供调度,则原 DM-worker 相关的数据迁移任务将无法进行。
注意:
当数据迁移任务处于全量导出或导入阶段时,该迁移任务暂不支持高可用,主要原因为:
- 对于全量导出,MySQL 暂不支持指定从特定快照点导出,也就是说数据迁移任务被重新调度或重启后,无法继续从前一次中断时刻继续导出。
- 对于全量导入,DM-worker 暂不支持跨节点读取全量导出数据,也就是说数据迁移任务被调度到的新 DM-worker 节点无法读取调度发生前原 DM-worker 节点上的全量导出数据。
迁移功能介绍
下面简单介绍 DM 数据迁移功能的核心特性。
Table routing
Table Routing 是指将上游 MySQL 或 MariaDB 实例的某些表迁移到下游指定表的路由功能,可以用于分库分表的合并迁移。
Block & allow table lists
Block & Allow Lists 是指上游数据库实例表的黑白名单过滤规则。其过滤规则类似于 MySQL replication-rules-db / replication-rules-table ,可以用来过滤或只迁移某些数据库或某些表的所有操作。
Binlog event filter
Binlog Event Filter 是比库表迁移黑白名单更加细粒度的过滤规则,可以指定只迁移或者过滤掉某些 schema / table 的指定类型的 binlog events,比如 INSERT , TRUNCATE TABLE 。
Shard support
DM 支持对原分库分表进行合库合表操作,但需要满足一些使用限制,详细信息请参考悲观模式分库分表合并迁移使用限制和乐观模式分库分表合并迁移使用限制。
使用限制
在使用 DM 工具之前,需了解以下限制:
- 数据库版本
- 5.5 < MySQL 版本 < 8.0
- MariaDB 版本 >= 10.1.2
注意:
如果上游 MySQL/MariaDB server 间构成主从复制结构,则需要 5.7.1 < MySQL 版本 < 8.0 或者 MariaDB 版本 >= 10.1.3。
在使用 dmctl 启动任务时,DM 会自动对任务上下游数据库的配置、权限等进行前置检查。
- DDL 语法
- 目前,TiDB 部分兼容 MySQL 支持的 DDL 语句。因为 DM 使用 TiDB parser 来解析处理 DDL 语句,所以目前仅支持 TiDB parser 支持的 DDL 语法。详见 TiDB DDL 语法支持。
- DM 遇到不兼容的 DDL 语句时会报错。要解决此报错,需要使用 dmctl 手动处理,要么跳过该 DDL 语句,要么用指定的 DDL 语句来替换它。详见如何处理不兼容的 DDL 语句。
- 分库分表
- 如果业务分库分表之间存在数据冲突,可以参考自增主键冲突处理来解决;否则不推荐使用 DM 进行迁移,如果进行迁移则有冲突的数据会相互覆盖造成数据丢失。
- 关于分库分表合并场景的其它限制,参见悲观模式下分库分表合并迁移使用限制以及乐观模式下分库分表合并迁移使用限制。
- 操作限制
- 在一些情况下,DM-worker 重启后不能自动恢复 DDL lock 同步,需要手动处理。详见手动处理 Sharding DDL Lock。
- DM-worker 切换 MySQL
- 当 DM-worker 通过虚拟 IP(VIP)连接到 MySQL 且要切换 VIP 指向的 MySQL 实例时,DM 内部不同的 connection 可能会同时连接到切换前后不同的 MySQL 实例,造成 DM 拉取的 binlog 与从上游获取到的其他状态不一致,从而导致难以预期的异常行为甚至数据损坏。如需切换 VIP 指向的 MySQL 实例,请参考虚拟 IP 环境下的上游主从切换对 DM 手动执行变更。