Redis监控状态
持久化文件监控
Redis 监控最直接的方法当然就是使用系统提供的 info 命令来做了,只需要执行下面一条命令,就能获得 Redis 系统的状态报告。
redis-cli info |
RDB文件状态监控
其中跟RDB文件状态监控相关的参数
- rdb_changes_since_last_save 表明上次RDB保存以后改变的key次数
- rdb_bgsave_in_progress 表示当前是否在进行bgsave操作。是为1
- rdb_last_save_time 上次保存RDB文件的时间戳
- rdb_last_bgsave_time_sec 上次保存的耗时
- rdb_last_bgsave_status 上次保存的状态
- rdb_current_bgsave_time_sec 目前保存RDB文件已花费的时间
- rdb_bgsave_in_progress 表示当前是否在进行bgsave操作。是为1
AOF文件状态监控
其中跟AOF文件状态监控相关的参数
- aof_enabled AOF文件是否启用
- aof_rewrite_in_progress 表示当前是否在进行写入AOF文件操作
- aof_rewrite_scheduled
- aof_last_rewrite_time_sec 上次写入的时间戳
- aof_current_rewrite_time_sec:-1
- aof_last_bgrewrite_status:ok 上次写入状态
- aof_last_write_status:ok 上次写入状态
- aof_rewrite_in_progress 表示当前是否在进行写入AOF文件操作
查看rdb文件生成耗时
在我们优化master之前,可以看看目前我们的其中一个生产环境的的redis的持久化状态
# Persistence |
通过redis-cli的info命令,可以看到 「rdb_last_bgsave_time_sec」参数的值,
这个值表示上次bgsave命令执行的时间。在磁盘IO定量的情况下,redis占用的内存越大,
这个值也就越大。通常「rdb_last_bgsave_time_sec」这个时间取决于两个因素:
- REDIS占用的内存大小
- 磁盘的写速度。
rdb_last_bgsave_time_sec:85这个标识表示我们上次保存dump RDB文件的时间。这个耗时受限于上面提到的两个因素。
当redis处于 rdb_bgsave_in_progress状态时,通过vmstat命令查看性能,得到wa值偏高,也就是说CPU在等待
IO的请求完成,我们线上的一个应用redis占用的内存是5G左右,也就是redis会生成大约5G左右的dump.rdb文件
vmstat命令
r b swpd free buff cache si so bi bo in cs us sy id wa st |
通过上面的输出,看到BGSAVE 对于IO的性能影响比较大
那么该如何解决由RDB文件带来的性能上不足的问题,又能保证数据持久化的目的
通常的设计思路就是利用「Replication」机制来解决:即master不开启RDB日志和AOF日志,来保证master的读写性能。而slave则开启rdb和aof来进行持久化,保证数据的持久性,
Redis 故障解决实例
Redis 各类 timeout 问题的原因和处理
故障症状:客户端报错 timeout
故障原因:多种原因都可能
故障类型:多种类型
故障解决方案:
什么是timeout呢?
所谓timeout就是超过业务方设定的超时时间依然得不到响应,就可以认为是timeout了,因为一般的redis请求基本上都是毫秒级别的,而业务一般会设置几十秒甚至一二百秒作为超时时间限制。一但Redis的延时过高,超过了业务设定的时间限制,就会出现timeout问题。
造成timeout超时的原因可能有哪些呢?
在部署了监控系统的前提下,可以先通过监控数据进行分析,寻找问题的方向。
如果没能得到什么有价值的信息的话,也可以从以下几个方面进行排查:
一、慢查询
确认是否使用慢查询,可以使用slowlog get num查看相应的慢命令:
127.0.0.1:6379> SLOWLOG get 10
1) (integer) 4 #慢操作索引
2) (integer) 1466059344 #事件发生的Unix时间戳
3 ) (integer) 250133 #事件耗时微妙(0.25s,250ms,250133us)
4) “debug” #时间具体命令以及相应参数
2) “sleep”
3) “.25”
127.0.0.1:6379> CONFIG SET slowlog-log-slower-than 1000 #设置当key的操作超过多长时间就会别加入到slowlog队列 默认单位us(0.001s) 默认是超过10ms。
注意:
unix时间戳转换方式:
date -d@’1466059344’ “+ %Y-%m-%d %H:%M:%S”
date -d”2016-06-16 16:50:50” ‘+%s’
注意:一般大量的key删除操作,以及keys遍历操作都可能会造成超时
参考:http://redis.io/commands/slowlog
二、几个关键项
查看redis状态的几个关键项:内存使用情况,当前链接客户端数量,ops等;
使用info命令其实就可以看出来具体的状态信息,具体后续再分析。
三、透明大页
查看透明大页是否禁止掉(Transparent huge pages);
官方建议是禁止掉比较好,线上测试其实效果不是特别明显;
linux下查看默认内存页大小(getconf PAGESIZE),默认是4K;
设置hugepage的数量;sysctl vm.nr_hugepages = 1024
echo never > /sys/kernel/mm/transparent_hugepage/enabled
四、是否为虚拟机
查看redis主机是否为虚拟机,这样会有内在延迟;
测试延迟:
./redis-cli —intrinsic-latency 100
这个命令可以在server段进行判断是否redis有延迟,在客户端通过-h -p 参数可以进行对比一下是否为网络上的影响。
五、启用延迟监控
启用延迟监控:
latency monitoring:
- 可以找出相应的延迟的敏感代码路径
- 延迟记录按照不同的时间进行时间流分隔统计
- 从时间序列中获取原始数据并进行报表
- 分析报表并提供人类可读的报告,并且根据度量值进行判断
时间序列(time series):
- 每个时间延迟任务都会记录到时间序列
- 每个时间序列包含160个元素
- 每个元素为一组:unix时间戳和事件执行所消耗的时间长
- 同一时间同一事件发生的延迟时间是会记录在一个时间序列。因此即使一个给定事件连续的延迟是可以衡量的(比如用户设置临界值太低),也至少得180s才能可达
- 最大延迟时间中的每一个元素都会被记录下来
怎样启用latency monitoring:
首先对于用户场景来说,什么是高延迟。应用请求查询少于1ms并且短时间有比较少客户端的应用经历2m的延迟是可以接受的。
因此,开启latency monitor首先需要设置延迟时间阈值在毫秒级别(latency threshold)。
当然了,也需要根据实际情况进行设定相应的值了。
CONFIG SET latency-monitor-threshold 100
(latency-monitor的阈值不能大于slowlog的值)
注意:延迟监控所需要的内存是非常小的,当然能增加内存是最好的啦。
latency命令报告出来的相关信息:
用户接口使用latency命令进行调用,同时参数后面可以接很多其他的子命令latency latest 记录最后的延迟事件的记录。每个事件包含以下几个变量:(事件名、事件延迟状态时间戳、延迟时间ms、此时间最大延迟):
127.0.0.1:6379> latency latest
1) 1) “command” #事件为command
2) (integer) 1466059344 #2016-6-16 14:42:24
3) (integer) 250 #延迟时间0.25s
4) (integer) 1000 #command事件延迟最大时间为1s
latency history events 此命令可以打印相应延迟事件相关的时间和耗时
127.0.0.1:6379> latency history command
1) 1) (integer) 1466059051
2) (integer) 10
2) 1) (integer) 1466059324
2) (integer) 13
3) 1) (integer) 1466059332
2) (integer) 1000
4) 1) (integer) 1466059344
2) (integer) 250
latency reset cevents 重置事件的相关延迟操作,清空记录:
127.0.0.1:6379> latency reset command
(integer) 1
127.0.0.1:6379> latency graph command
command - high 700 ms, low 100 ms (all time high 700 ms)
o#
_#||
o||||
_#|||||
2222111
6421961
sssssss
另外,一般情况下大量的删除,过期以及淘汰(由maxmemory-policy控制的)的大对象,也会造成redis阻塞,进而造成相应的延迟。如果经常有比较大的对象进行删除,过期和淘汰的,建议将这些对象分割成一些小对象。即对比较大的key进行拆分。
参考:http://redis.io/topics/latency-monitor
六、持久化对延迟
持久化对延迟造成的影响:
一般情况来说,持久话的也会影响延迟,因为持久话操作必须对内存中的数据线进行一次save操作。因此必须根据以下相关的参数进行持久性(durability)和延迟/性能(latency/performance)做相应的权衡:
1.AOF + fsync always:这种方式会比较慢一些;
2.AOF + fsync every second:这个将是这种的一种方案;
3.AOF + fsync every second + no-appendfsync-on-rewrite option set to yes: 比较好的一种方式,但是需要避免在往磁盘同步的时候进行fsync;
4.AOF + fsync never. 磁盘压力会比较小;
5.RDB.
用客户端连接 ApsaraDB for Redis 的时候显示密码不对
故障症状:ERR Authentication failed
故障原因:密码忘记或没有权限
故障类型:认证和权限
故障解决方案:
首先请确认您的 ApsaraDB for Redis 实例密码是否输入正确,如有必要可以通过控制台来修改密码。
如果您确认密码正确但用客户端连接 ApsaraDB for Redis 时显示密码不对,请检查您是否按照要求的格式输入了鉴权信息。ApsaraDB for Redis 的鉴权信息包括了(instanceId:password)两部分,请检查您在程序中是否输入了完整信息。
以 Java 代码为例,正确的代码应该是:
Jedis jedis = new Jedis(host, port);//鉴权信息由用户名:密码拼接而成jedis.auth(“instance_id:password”); |
如果您在代码中只输入了 password,如下
Jedis jedis = new Jedis(host, port);//鉴权信息缺少了instance_idjedis.auth(“password”);//错误 |
则在连接 ApsaraDB for Redis 时会得到如下的出错信息:
redis.clients.jedis.exceptions.JedisDataException: ERR Authentication failed. |
Node 连接 Redis,用户认证提示错误 “NOAUTH Authentication required ”
故障症状: “Ready check failed: NOAUTH Authentication required ”
故障原因:密码忘记或没有权限
故障类型:认证和权限
故障解决方案:
Node 客户端程序,在连接Redis的时候,提示错误信息 “Error:Ready check failed: NOAUTH Authentication required”。例如下图:

从提示的错误信息,可以看出是认证失败了,auth 这里填写的是 Redis 连接地址,正确的是写 Redis 实例 ID。
一般认证失败需要从两方面进行检查。
- 配置的密码是否正确。
- 认证的用户密码,是 Redis 实例 ID 加密码的方式,检查格式是否正确。
Jedis 连接池错误
故障症状: 使用 Jedis 连接池模式容易遇到无法获取连接池的错误如下所示。
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool |
故障原因:多种原因
故障类型:认证和权限
故障解决方案:
可以根据以以下几种原因进行分类排查。
网络检查
首先检查是否网络问题,可以通过telnet host 6379进行简单测试,连上之后auth 密码回车查看是否返回+OK\r\n,如果能够正确返回继续检查ping请求或者读写请求是否正常返回,操作多次排查网络问题影响。
JedisPool 连接数设置检查
JedisPool 使用的时候需要进行连接池的设置,用户在超过 MaxTotal 连接数的时候也会出现获取不到连接池的情况,这个时候可以在访问客户端上通过netstat -an | grep 6379 | grep EST | wc -l查看链接的客户端链接数目,并且比较这个数目和 JedisPool 配置的 MaxTotal 的值,如果没有明显超过或者接近就可以排除 JedisPool 连接池配置的影响。
JedisPool 连接池代码检查
对于 JedisPool 连接池的操作,每次 getResource 之后需要调用 returnResource 或者 close 进行归还,可以查看代码是否是正确使用,代码示例如下:
JedisPoolConfig config = new JedisPoolConfig();//最大空闲连接数, 应用自己评估,不要超过ApsaraDB for Redis每个实例最大的连接数config.setMaxIdle(200);//最大连接数, 应用自己评估,不要超过ApsaraDB for Redis每个实例最大的连接数config.setMaxTotal(300);config.setTestOnBorrow(false);config.setTestOnReturn(false);String host = "*.aliyuncs.com";String password = "密码";JedisPool pool = new JedisPool(config, host, 6379, 3000, password);Jedis jedis = null;try { jedis = pool.getResource(); /// ... do stuff here ... for example jedis.set("foo", "bar"); String foobar = jedis.get("foo"); jedis.zadd("sose", 0, "car"); jedis.zadd("sose", 0, "bike"); Set<String> sose = jedis.zrange("sose", 0, -1);} finally { if (jedis != null) { jedis.close(); }}/// ... when closing your application:pool.destroy(); |
检查是否发生 nf_conntrack 丢包
通过 dmesg 检查客户端是否有异常。
nf_conntrack: table full, dropping packet |
如果发生 nf_conntract 丢包可以修改设置 sysctl -w net.netfilter.nf_conntrack_max=120000。
检查是否 TIME_WAIT 问题
通过ss -s查看 time wait 链接是否过多。
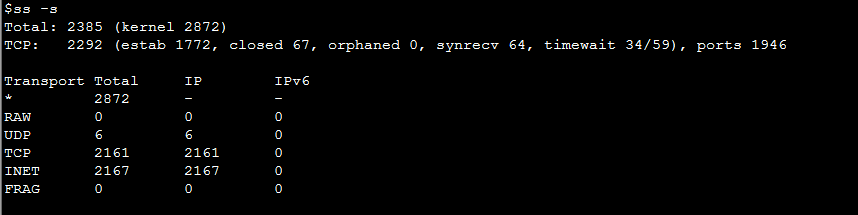
如果 TIME_WAIT 过多可以修改以下参数:
sysctl -w net.ipv4.tcp_max_tw_buckets=180000sysctl -w net.ipv4.tcp_tw_recycle=1 |
检查是否 DNS 解析问题
通过在 /etc/hosts 文件直接绑定 host 地址,绑定完成之后查看问题是否还存在,如果还存在则不是 DNS 解析问题。
192.168.1.1 *.redis.rds.aliyuncs.com |
需要帮助
如果按照上面排查之后还有问题可以通过抓包并将报错时间点、报错信息、抓包文件发送给阿里云售后同学进行分析。抓包命令为sudo tcpdump -i eth0 tcp and port 6379 -n -nn -s 74 -w redis.cap。
redis丢失数据案例
故障症状:
我们的一台redis服务器,硬件配置为4核,4G内存。redis持久话方案是RDB。前面几个月redis使用的 |
内存在1G左右。在一次重启之后,redis只恢复了部分数据,这时查看redis.log文件。看见了如下的错误
[23635] 25 Jul 08:30:54.059 * 10000 changes in 60 seconds. Saving... |
故障原因:参数设置有误
故障类型:服务器参数选项
故障解决方案:
这时,想起了redis启动时的警告
WARNING overcommit_memory is set to 0! |
翻译
警告:过量使用内存设置为0!在低内存环境下,后台保存可能失败。为了修正这个问题, |
vm.overcommit_memory不同的值说明
- 0 表示检查是否有足够的内存可用,如果是,允许分配;如果内存不够,拒绝该请求,并返回一个错误给应用程序。
- 1 允许分配超出物理内存加上交换内存的请求
- 2 内核总是返回true
- 1 允许分配超出物理内存加上交换内存的请求
redis的数据回写机制分为两种
- 同步回写即SAVE命令。redis主进程直接写数据到磁盘。当数据量大时,这个命令将阻塞,响应时间长
- 异步回写即BGSAVE命令。redis 主进程fork一个子进程,复制主进程的内存并通过子进程回写数据到磁盘。
由于RDB文件写的时候fork一个子进程。相当于复制了一个内存镜像。当时系统的内存是4G,而redis占用了近3G的内存,因此肯定会报内存无法分配。如果 「vm.overcommit_memory」设置为0,在可用内存不足的情况下,就无法分配新的内存。如果 「vm.overcommit_memory」设置为1。 那么redis将使用交换内存。
解决办法:
- 方法一: 修改内核参数 vi /etc/sysctl。设置vm.overcommit_memory = 1然后执行
sysctl -p
- 方法二: 使用交换内存并不是一个完美的方案。最好的办法是扩大物理内存。
redis 内存达到上限
故障症状:有运营的同事反应,系统在登录的情况下,操作时会无缘无故跳到登录页面。
故障原因:redis 内存达到上限
故障类型:服务器参数选项
故障解决方案:
由于我们的系统做了分布式的session,默认把session放到redis里,按照以往的故障经验。可能是redis使用了最大内存上限导致了无法设置key。
登录 redis 服务器查看 redis.conf 文件设置了最大8G内存「maxmemory 8G」
然后通过「redis-cli info memory 」 查询到目前的内存使用情况「used_memory_human:7.71G」
接着通过redis-cli工具设置值 。
报错 「OOM command not allowed when used memory 」。
再次验证了redis服务器已经达到了最大内存
解决方法:
- 关闭redis 服务器redis-cli shutdown
- 修改配置文件的最大内存 「maxmemory」
- 启动redis服务器redis-server redis.conf